Pythonで測定装置のcsvファイルをグラフ化するアプリを作る(1. データ表示編)
こんなのを作りました. drive.google.com できることは
- 複数のcsvを開いてデータを表示する(後から追加も可)
- グラフ(散布図,折線,棒,円,ヒストグラム,散布図行列)を描ける
- 散布図と折線のグラフは3次元も描ける
- 軸を常用対数に変換
- 表示したデータの内,選択したデータやフィルターした結果のみをグラフに反映
- 不要な列の削除
- 色,点や線の形状,行,列でデータを区別
- グラフのサイズ変更
です.最初に測定条件や要約情報が記載された後に,測定値が続くタイプのcsvを念頭に置いています.

そこでエクセル(GUIアプリケーション)しか使えない方々でも簡単にグラフを確認できる(はずの)アプリを冒頭の通り作成してみました.
これのpythonでの作り方を順に公開していきます. 今回はcsvデータの表示です.
目標
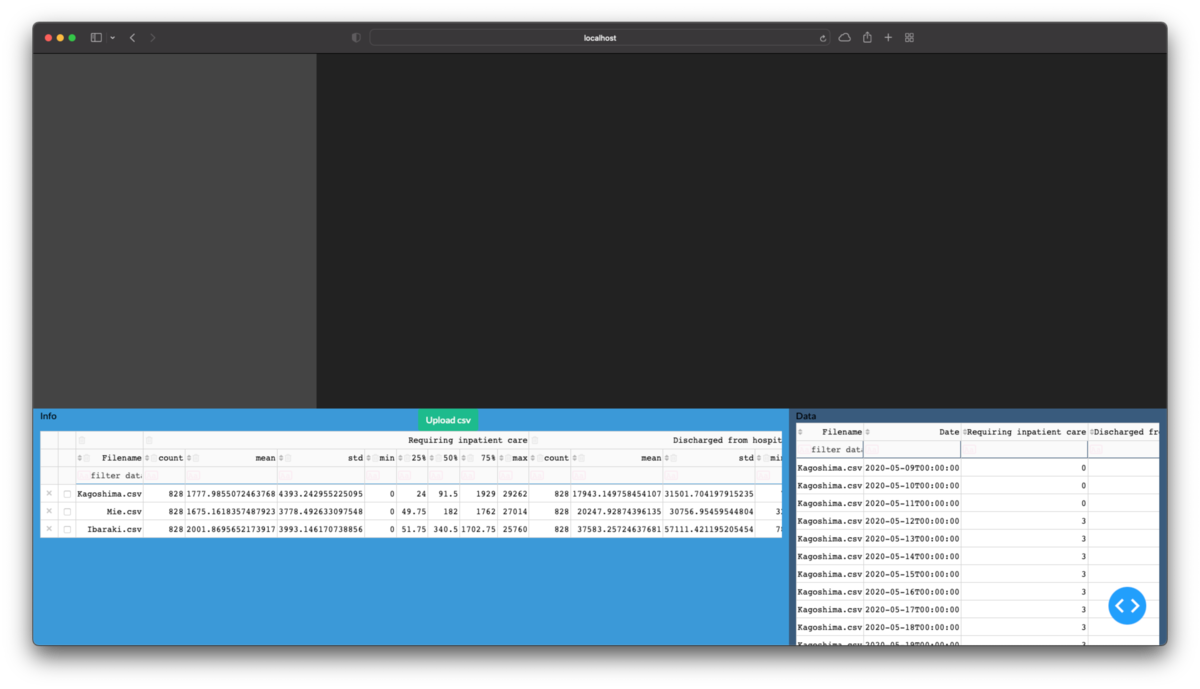
下図の赤枠部分を作成します.開発中に毎回csvをGUIで選択するのは面倒なので,その機能は連載の最後に実装します.
開発環境
私の環境は次の通りです.必要に応じてパッケージをインストールして下さい.
- MacBook Pro(Mid 2014), macOS Big Sur
- Python 3.7.5
- numpy 1.20.0
- pandas 1.2.1: データ処理に使用
- plotly 5.10.0: グラフ描画に使用
- dash 2.6.1: アプリのGUIに使用
- dash-bootstrap-components 1.2.1
- dash-daq 0.5.0
データの準備
公開できる測定データが手元になかったので,まずはデータを取得するところから始めます. 今回は厚労省が公開している新型コロナウイルス感染者数に関するデータを使います. ダウンロードしたままですと例題としては都合が悪いため簡単に編集します.
from pathlib import Path from datetime import datetime import pandas as pd df = pd.read_csv( 'https://covid19.mhlw.go.jp/public/opendata/requiring_inpatient_care_etc_daily.csv', header=0, index_col=0 ) wd = Path('COV19') try: wd.mkdir(exist_ok=False) except: pass # 都道府県ごとに3列単位になっているのを切り分ける for i in range(0,144,3): group = df.iloc[:, i:i+3] col = group.columns.str.extract( r'\((?P<prefecture>.+)\) (?P<param>.+)', expand=True ) prefecture = col['prefecture'].iat[0] group.columns = col['param'] # 測定条件に相当する部分の作成 data = f'''Title,入院治療等を要する者等推移 Prefecture,{prefecture} Date,{datetime.now().strftime("%Y-%m-%d %H:%M")} URL,https://covid19.mhlw.go.jp/public/opendata/requiring_inpatient_care_etc_daily.csv ''' # 要約情報の作成 data += group.describe().to_csv() data += '\n\n' data += group.to_csv() with open(wd/f'{prefecture}.csv', 'w') as f: f.write(data)
これで「測定条件 + 要約 + 測定データ」の形式のcsvが手に入りました.
csvを表示する機能の作成
csvを読み込む用のクラス作成
上で準備したcsvをpandasで読み込むためのクラスを作成します. 今回は簡単に読めるのでクラスにする必要もありませんが,実際の装置データの場合は測定条件と要約,測定値でそれぞれ基底クラスを作成した方が楽でしょう.
from io import StringIO class COV19(object): """csvを読み込みます.文字列を渡して解読させる方が後々で楽です. Attributes ----------- header: pd.Series 測定条件 info: pd.DataFrame 測定値の要約 data: pd.DataFrame 測定値 """ def load_string(self, string): """文字列の読み込み Parameter ----------- string: str 文字列化したcsvファイル """ header, info, data = string.split('\n\n') # 今回のcsvは一番簡単な例として空行で分かれてます self.header = pd.Series(StringIO(header)) self.info = pd.read_csv(StringIO(info), header=0, index_col=0) self.data = pd.read_csv(StringIO(data), header=0, index_col=0, parse_dates=['Date'] ) return self def load_file(self, filepath): with open(filepath, 'r') as f: self.load_string(f.read()) return self
csvの読み込み
読み込み用クラスをfor文で回してdictに格納します.できたdictはpd.DataFrameに変換します.
要約情報の列名をpd.MultiIndexにしてしまいましたが,グラフ作成やデータの結合時などの取扱が大変面倒になります.
例えば次節のプログラム中で表(dash.DataTable)のidに渡すとエラーになります.
このためpd.MultiIndexは避けた方が自分が楽になります.
n_data = 3# 47都道府県+全国を毎回読むのは非効率のため上限を設ける info = {} data = {} for root, dirnames, filenames in os.walk(Path.cwd()): for filename in filenames: if len(info)>=n_data: continue if not filename.lower().endswith('.csv'): continue filepath = Path(root)/filename with open(filepath, 'r') as f: cov = COV19().load_string(f.read()) info[filename] = cov.info data[filename] = cov.data df_info = pd.concat(info).unstack().rename_axis(['Filename'], axis=0) col_flat = (['Filename'] + ['_'.join(c) for c in df_info.columns]) col_multi = [('', 'Filename')] + df_info.columns.to_list() df_info = df_info.reset_index().set_axis(col_flat, axis=1) df_detail = pd.concat(data).rename_axis( ['Filename', 'Date'], axis=0).reset_index()
画面への表示
まずは要約情報だけを表示し,その次に測定値のパーツを足します.表の使い方はdashの公式ドキュメントを確認して下さい.
今回は特に並べ替えとフィルタの部分を使用しています.
レイアウト作成についてはこちらのページが参考になりますが,
きちんと公式サイトを読んで引数に何が渡せるか確認しましょう.
またどんなテーマがいいかはこちらのサイトで比較できます.
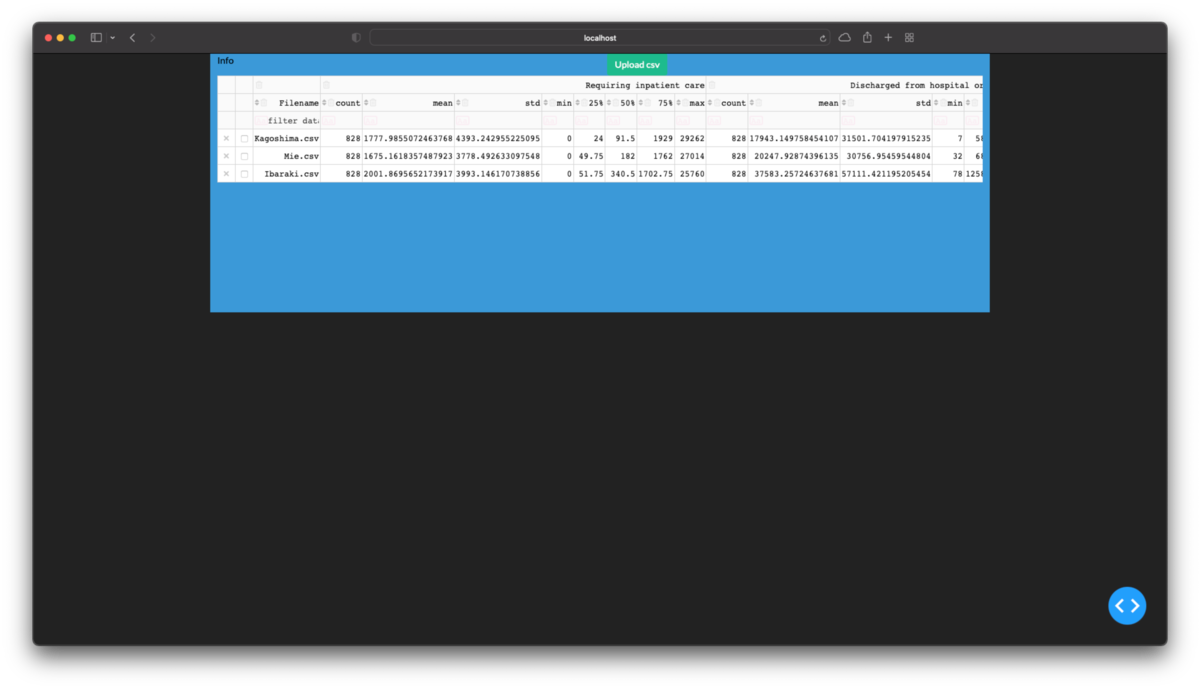
dbc_css = "https://cdn.jsdelivr.net/gh/AnnMarieW/dash-bootstrap-templates/dbc.min.css" app = Dash(external_stylesheets=[dbc.themes.DARKLY, dbc_css]) table_info = html.Div( [dbc.Row( [dbc.Col('Info'), dbc.Col( dcc.Upload( dbc.Button('Upload csv', color='success'), id='upload-csv', multiple=True ) ), ], justify='between', ), dbc.Row( [DataTable( data=df_info.to_dict('records'), columns=[ {'name': m, 'id': f, 'deletable': True} for f, m in zip(col_flat, col_multi) ], id='table_info', editable=True, filter_action='native', sort_action='native', merge_duplicate_headers=True, row_selectable='multi', row_deletable=True, style_table={'overflow': 'auto', 'height': '40vh'}, ), ] ) ] ) container = [ dbc.Row( [dbc.Col(table_info, class_name='bg-info text-black')], style={'height': '40vh'} ) ] app.layout = dbc.Container(container, fluid=False) if __name__=='__main__': app.run_server(debug=True)
ここまでを実行し,ブラウザのURL欄にlocalhost:8050を入力して開くと次の画像のようになるはずです.
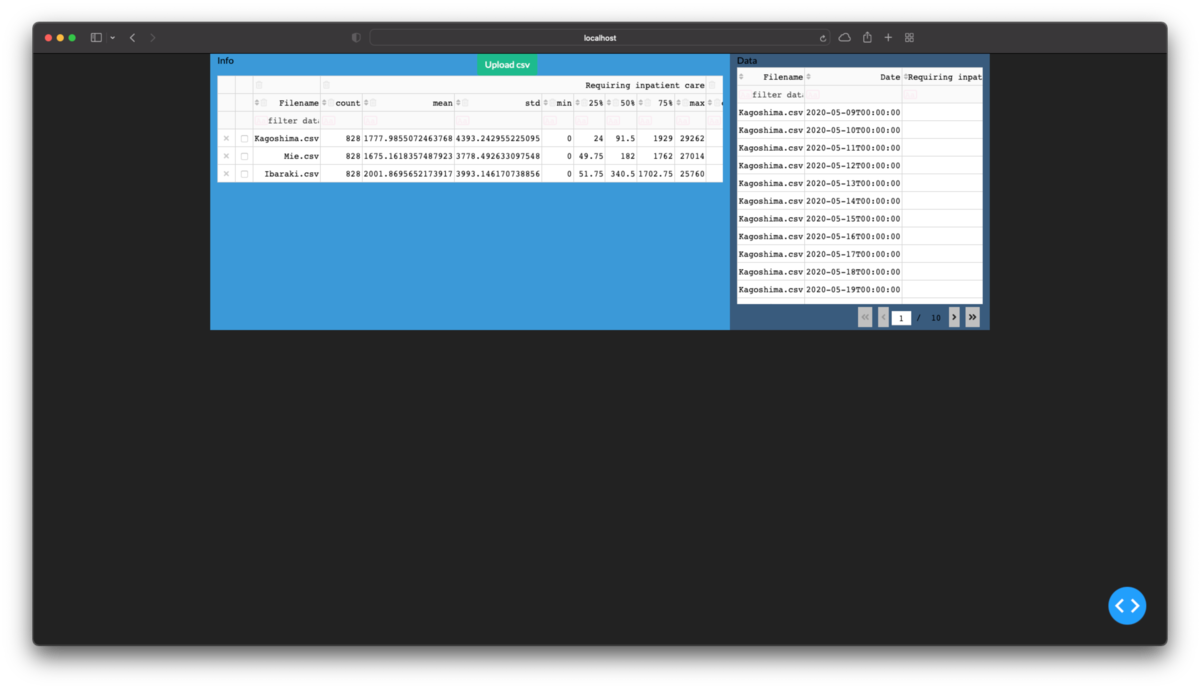
次に測定値のパーツを作成します.それをcontainerに追加するとwebページに反映できます.
# table_infoの定義部分 table_detail = html.Div( ['Data', DataTable( data=df_detail.to_dict('records'), columns=[{'name': i, 'id': i} for i in df_detail.columns], id='table_detail', editable=True, filter_action='native', sort_action='native', style_table={'overflow': 'scroll', 'height': '40vh'}# scrollの設定がないとページが長くなったりエリア分けを突き抜けたりします ), dcc.Store(id='store_detail', data=df_detail.to_json(orient='records')),# 後で使います ] ) container = [ dbc.Row( [dbc.Col(table_info, width=8, class_name='bg-info text-black'), dbc.Col(table_detail, width=4, class_name='bg-primary text-black'), ], style={'height': '40vh'} ) ]
フィルター機能の搭載
「とりあえず全部開いたけどやっぱり個別に確認したい」ということはよくあります.なので要約情報の表でチェックをつけたファイルのみを表示できるように, 次のコールバック関数を追加します.またこの関数によって要約情報の表でフィルタかけると測定値の表にも反映されるようになります.
@app.callback( Output('table_detail', 'data'), Output('table_detail', 'columns'), Input('table_info', 'derived_virtual_selected_rows'), Input('store_detail', 'data'),# 別の場所からコピーしないと選択されなかったデータが消えます State('table_info', 'derived_virtual_data'),# フィルタ済みのデータを使用します #prevent_initial_call=True, ) def select_file(selected_rows, data_detail, data_info): # 起動時は[]ということになっているが,Noneになっていてエラーになる場合に対処 if data_info is None: data_info = [] df_info = pd.DataFrame(data_info) if data_detail is None: df_detail = pd.DataFrame() else: df_detail = pd.read_json( data_detail, orient='records', convert_dates=['Date']) if selected_rows is None: selected_rows = [] if len(selected_rows)!=0: filenames = df_info['Filename'].iloc[selected_rows].to_list() df_detail = df_detail.loc[ lambda d: d['Filename'].apply(lambda x: x in filenames) ] columns=[{'name': i, 'id': i} for i in df_detail.columns] return df_detail.to_dict('records'), columns
アプリ上で表を配置する
主役たるグラフの下に表を配置するように設定します.
container = [
dbc.Row(
[dbc.Col([], width=3, class_name='bg-secondary',
style={'height': '60vh', 'overflow': 'scroll'},
),
dbc.Col(
[], width=9, style={'height': '60vh', 'overflow': 'scroll'}),
],
),
dbc.Row(
[dbc.Col(table_info, width=8, class_name='bg-info text-black'),
dbc.Col(table_detail, width=4, class_name='bg-primary text-black'),
], style={'height': '40vh'},
),
]
app.layout = dbc.Container(container, fluid=True)# 画面全体を使うようにfluid=Trueに変更