Pythonで測定装置のcsvファイルをグラフ化するアプリを作る(5. ファイルダイアログからのcsv選択編)
続きものの最終回です.こんなのの作り方を公開していきます. drive.google.com
これまで4回に分けて公開しています.
今回はずっと固定だったcsvファイルを選択できるようにします.また以前までのも含めてコードはご自身の責任でご自由にご使用下さい.
目標
ファイルダイアログからcsvを自由に選択,追加できるようにする.
環境
今まで通りPythonでpandasとdashをインストールして下さい.
実装
アップロードされたファイルをデコードする
dashの公式ドキュメントを参考にします.
dcc.Uploadで読み込んだファイルはbase64という形式でエンコードされるそうで,csvとして扱うためにはUTF-8やshift-jisでデコードする必要があります.
Pythonで作ったファイルであればUTF-8になっているはずですし,測定装置から出力されたファイルはshift-jisになっているでしょう.
import base64 # ファイル単体を読み取る関数 def parse_content(contents, filename): content_type, content = contents.split(',') decode = base64.b64decode(content) f = decode.decode('utf-8')# もしくはshift-jis try: data = COV19().load_string(f) info = data.info detail = data.data except: info = detail = None return info, detail # dcc.Uploadの出力を受け取って全ファイルをまとめる関数 def load_contents(contents, filenames): info = {} detail = {} for c, n in zip(contents, filenames): info[n], detail[n] = parse_content(c, n) info = pd.concat(info).unstack().rename_axis(['Filename'], axis=0) detail = pd.concat(detail).rename_axis( ['Filename', 'Date'], axis=0).reset_index() return info, detail
アップロードされたファイルを表に出力する
既存の表に新規データを追加します.
@app.callback( Output('table_info', 'data'), Output('table_info', 'columns'), Output('store_detail', 'data'), inputs={'contents': Input('upload-csv', 'contents')}, state={ 'filenames': State('upload-csv', 'filename'), 'col_info': State('table_info', 'columns'), 'data_info': State('table_info', 'data'), 'data_detail': State('store_detail', 'data'),# フィルタされているデータに追加すると非表示データが消える }, prevent_initial_call=True ) def update_csv( contents, filenames, col_info, data_info, data_detail): if data_info is None: df_info = pd.DataFrame() else: df_info = pd.DataFrame(data_info) col_info = pd.MultiIndex.from_tuples([c['name'] for c in col_info]) df_info = df_info.set_axis(col_info, axis=1).set_index( ('', 'Filename')).rename_axis('Filename', axis=0) if data_detail is None: df_detail = pd.DataFrame() else: df_detail = pd.read_json( data_detail, orient='records', convert_dates=['Date']) if contents is not None: info, detail = load_contents(contents, filenames) df_info = pd.concat([df_info, info]).drop_duplicates() df_detail = pd.concat([df_detail, detail]).reset_index( drop=True).drop_duplicates() col_flat = (['Filename'] + ['_'.join(c) for c in df_info.columns]) col_multi = [('', 'Filename')] + df_info.columns.to_list() df_info = df_info.reset_index().set_axis(col_flat, axis=1) columns=[ {'name': m, 'id': f, 'deletable': True} for f, m in zip(col_flat, col_multi) ] return df_info.to_dict('records'), columns, df_detail.to_json(orient='records')
不要な部分の削除
不要になったので次の記述を削除します.
n_data = 3# 47都道府県+全国を毎回読むのは非効率のため上限を設ける info = {} data = {} for root, dirnames, filenames in os.walk(Path.cwd()): for filename in filenames: if len(info)>=n_data: continue if not filename.lower().endswith('.csv'): continue filepath = Path(root)/filename with open(filepath, 'r') as f: cov = COV19().load_string(f.read()) info[filename] = cov.info data[filename] = cov.data df_info = pd.concat(info).unstack().rename_axis(['Filename'], axis=0) col_flat = (['Filename'] + ['_'.join(c) for c in df_info.columns]) col_multi = [('', 'Filename')] + df_info.columns.to_list() df_info = df_info.reset_index().set_axis(col_flat, axis=1) df_detail = pd.concat(data).rename_axis( ['Filename', 'Date'], axis=0).reset_index()
表のデータと列も削除します.
table_info = html.Div(
[dbc.Row(
[dbc.Col('Info'),
dbc.Col(
dcc.Upload(
dbc.Button('Upload csv', color='success'),
id='upload-csv', multiple=True
)
),
], justify='between',
),
dbc.Row(
[DataTable(
#data=df_info.to_dict('records'),
#columns=[
# {'name': m, 'id': f, 'deletable': True}
# for f, m in zip(col_flat, col_multi)
# ],
id='table_info', editable=True, filter_action='native',
sort_action='native', merge_duplicate_headers=True,
row_selectable='multi', row_deletable=True,
style_table={'overflow': 'auto', 'height': '40vh'},
),
]
)
]
)
table_detail = html.Div(
['Data',
DataTable(
#data=df_detail.to_dict('records'),
#columns=[{'name': i, 'id': i} for i in df_detail.columns],
id='table_detail', editable=True, filter_action='native',
sort_action='native',
style_table={'overflow': 'scroll', 'height': '40vh'}
),
dcc.Store(id='store_detail')#, data=df_detail.to_json(orient='records')),
]
)
ようやく完成です.
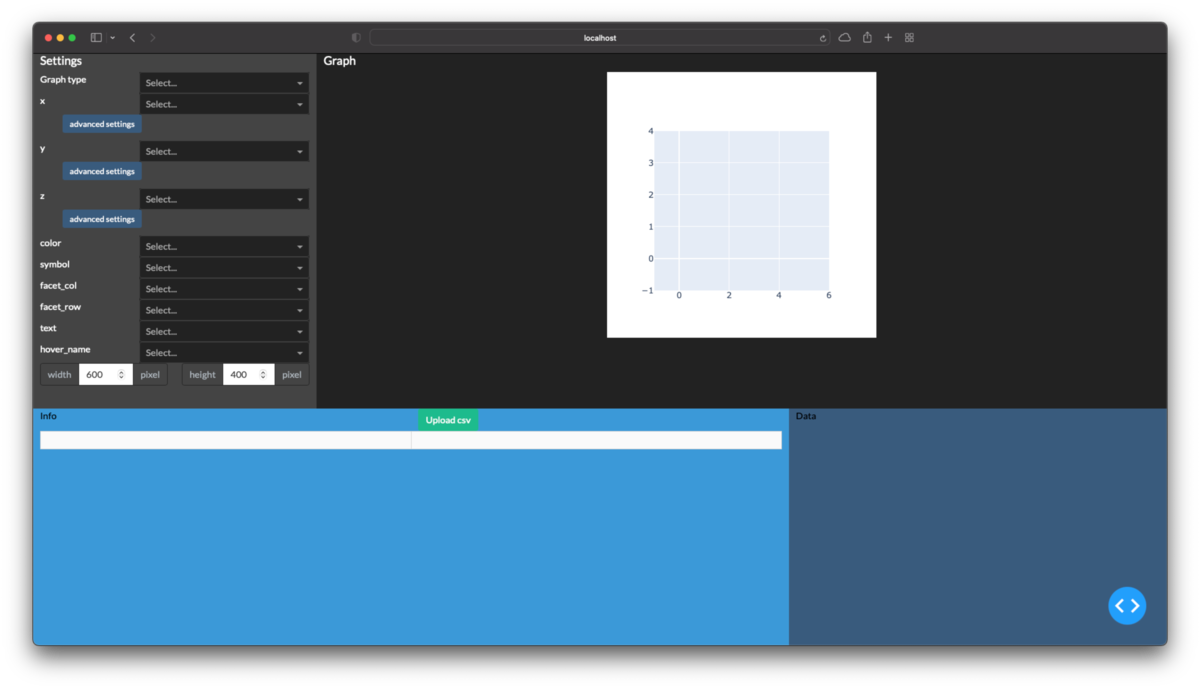
完成したコード全体
ご自身の責任でご自由に使用,改変,再配布して下さい.
from io import StringIO import base64 import pandas as pd from dash import Dash, html, dcc from dash import Input, State, Output from dash.dash_table import DataTable import dash_daq as daq import dash_bootstrap_components as dbc from plotly import express as px from plotly import graph_objects as go class COV19(object): def load_string(self, string): header, info, data = string.split('\n\n') self.header = pd.Series(StringIO(header)) self.info = pd.read_csv(StringIO(info), header=0, index_col=0) self.data = pd.read_csv(StringIO(data), header=0, index_col=0, parse_dates=['Date']) return self def load_file(self, filepath): with open(filepath, 'r') as f: self.load_string(f.read()) return self class Components(object): def __init__(self, name): self.name = name def make_dropdown(self, multi=False): return dbc.Row( [dbc.Col(f'{self.name}'), dbc.Col( dcc.Dropdown( options=[], value=None, multi=multi, id=f'graph-{self.name}', className='dbc', style={'width': '15vw', 'float': 'right'}, ) ), ], ) def make_button(self): return dbc.Button( 'advanced settings', n_clicks=0, id=f'{self.name}-button', size='sm', style={'width': '7vw'}, ) def make_range(self): return [ html.Div('Range', style={'text-align': 'center'}), dbc.InputGroup( [dbc.Input( placeholder='min', id=f'{self.name}min', type='number', ), dbc.InputGroupText('–'), dbc.Input( placeholder='max', id=f'{self.name}max', type='number', ), ], ), ] def make_toggle(self): return daq.BooleanSwitch( on=False, id=f'graph-log_{self.name}', label=f'log {self.name}', labelPosition='top', ) def make_errorbar(self): return [ html.Div( 'Error bar', style={'text-align': 'center'}, ), dbc.InputGroup( [dbc.Input( placeholder='None or lower limit', id=f'error_{self.name}_minus', type='number', ), dbc.InputGroupText('–'), dbc.Input( placeholder='size or upper limit', id=f'error_{self.name}', type='number', ), ], ), ] def make_collapse(self): button = self.make_button() options = dbc.Row( [dbc.Col(self.make_range()), dbc.Col(self.make_toggle())]) collapse = dbc.Collapse( options, is_open=False, id=f'{self.name}_collapse') return dbc.Col( [button, collapse], width={'offset': 1}, style={'padding-bottom': '10pt'}, ) class Axis(Components): def make_component(self, multi=False): components = [self.make_dropdown(multi), self.make_collapse()] return html.Div(components) dbc_css = "https://cdn.jsdelivr.net/gh/AnnMarieW/dash-bootstrap-templates/dbc.min.css" app = Dash(external_stylesheets=[dbc.themes.DARKLY, dbc_css]) table_info = html.Div( [dbc.Row( [dbc.Col('Info'), dbc.Col( dcc.Upload( dbc.Button('Upload csv', color='success'), id='upload-csv', multiple=True ) ), ], justify='between', ), dbc.Row( [DataTable( id='table_info', editable=True, filter_action='native', sort_action='native', merge_duplicate_headers=True, row_selectable='multi', row_deletable=True, style_table={'overflow': 'auto', 'height': '40vh'}, ), ] ) ] ) table_detail = html.Div( ['Data', DataTable( id='table_detail', editable=True, filter_action='native', sort_action='native', style_table={'overflow': 'scroll', 'height': '40vh'} ), dcc.Store(id='store_detail'), ] ) graph_type = dbc.Row( [dbc.Col(['Graph type']), dbc.Col( [dcc.Dropdown( options=[ {'label': '散布図','value': 'scatter'}, {'label': '折線', 'value': 'line'}, {'label': '棒', 'value': 'box'}, {'label': 'ヒストグラム', 'value': 'histogram'}, {'label': '円', 'value': 'pie'}, {'label': '散布図行列', 'value': 'scatter_matrix'}, ], id='graph-type', value=None, className='dbc', style={'width': '15vw', 'float': 'right'}, ), ] ), ] ) graph = [dbc.Row(dbc.Col(html.H5(['Graph']))), dbc.Row( [dbc.Col(width=0), dbc.Col(dcc.Graph(id='graph')), dbc.Col(width=0)], justify='center' ), ] graph_settings = [ html.H5(['Settings']), graph_type, Axis('x').make_component(multi=True), Axis('y').make_component(multi=False), Axis('z').make_component(multi=False), Components('color').make_dropdown(), Components('symbol').make_dropdown(), Components('facet_col').make_dropdown(), Components('facet_row').make_dropdown(), Components('text').make_dropdown(), Components('hover_name').make_dropdown(), dbc.Row( [dbc.Col( dbc.InputGroup( [dbc.InputGroupText('width'), dbc.Input(value=600, type='number', id='graph-width'), dbc.InputGroupText('pixel') ] ) ), dbc.Col( dbc.InputGroup( [dbc.InputGroupText('height'), dbc.Input(type='number', value=400, id='graph-height'), dbc.InputGroupText('pixel') ], ) ) ], ), ] container = [ dbc.Row( [dbc.Col(graph_settings, width=3, class_name='bg-secondary', style={'height': '60vh', 'overflow': 'scroll'}, ), dbc.Col( graph, width=9, style={'height': '60vh', 'overflow': 'scroll'}), ], ), dbc.Row( [dbc.Col(table_info, width=8, class_name='bg-info text-black'), dbc.Col(table_detail, width=4, class_name='bg-primary text-black'), ], style={'height': '40vh'}, ), ] app.layout = dbc.Container(container, fluid=True) @app.callback( Output('table_detail', 'data'), Output('table_detail', 'columns'), Input('table_info', 'derived_virtual_selected_rows'), Input('store_detail', 'data'), State('table_info', 'derived_virtual_data'), #prevent_initial_call=True, ) def select_file(selected_rows, data_detail, data_info): if data_info is None: data_info = [] df_info = pd.DataFrame(data_info) if data_detail is None: df_detail = pd.DataFrame() else: df_detail = pd.read_json( data_detail, orient='records', convert_dates=['Date']) if selected_rows is None: selected_rows = [] if len(selected_rows)!=0: filenames = df_info['Filename'].iloc[selected_rows].to_list() df_detail = df_detail.loc[ lambda d: d['Filename'].apply(lambda x: x in filenames) ] columns=[{'name': i, 'id': i} for i in df_detail.columns] return df_detail.to_dict('records'), columns def drawer_px(graph_type, graph_kws, axis_ranges, log_axis): if graph_type!='scatter_matrix': graph_kws['x'] = graph_kws['x'][0] if graph_type=='scatter': if graph_kws['z'] is None: drawer = px.scatter graph_kws.pop('z') else: drawer = px.scatter_3d graph_kws.pop('facet_col') graph_kws.pop('facet_row') elif graph_type=='line': if graph_kws['z'] is None: drawer = px.line graph_kws.pop('z') else: drawer = px.line_3d graph_kws.pop('facet_col') graph_kws.pop('facet_row') else: graph_kws.pop('z') graph_kws.pop('text') drawer = None if graph_type=='box': drawer = px.box graph_kws.pop('symbol') elif graph_type=='histogram': drawer = px.histogram graph_kws.pop('symbol') elif graph_type=='pie': graph_kws.pop('symbol') drawer = px.pie graph_kws['names'] = graph_kws.pop('x') graph_kws['values'] = graph_kws.pop('y') elif graph_type=='scatter_matrix': drawer = px.scatter_matrix graph_kws['dimensions'] = graph_kws.pop('x') graph_kws.pop('y') graph_kws.pop('facet_col') graph_kws.pop('facet_row') for key in 'xyz': if key not in graph_kws.keys(): continue keymin = axis_ranges[f'{key}min'] keymax = axis_ranges[f'{key}max'] if (keymin is not None and keymax is not None ): graph_kws[f'range_{key}'] = [keymin, keymax] graph_kws[f'log_{key}'] = log_axis[f'log_{key}'] return drawer, graph_kws dropdowns = ['x', 'y', 'z', 'color', 'symbol', 'facet_col', 'facet_row', 'text', 'hover_name' ] @app.callback( Output('graph', 'figure'), inputs={ 'data_info': Input('table_info', 'derived_virtual_data'), 'data_detail': Input('table_detail', 'derived_virtual_data'), 'graph_type': Input('graph-type', 'value'), 'graph_kws': { key: Input(f'graph-{key}', 'value') for key in dropdowns + ['width', 'height'] }, 'log_axis': {f'log_{x}': Input(f'graph-log_{x}', 'on') for x in 'xyz'}, 'axis_ranges': { f'{key}': Input(f'{key}', 'value') for key in [f'{x}min' for x in 'xyz']+[f'{x}max' for x in 'xyz'] }, }, prevent_initial_call=True, ) def update_graph( data_info, data_detail, graph_kws, axis_ranges, log_axis, graph_type, ): if len(data_info)==0: return go.Figure() df = pd.DataFrame(data_info) if len(data_detail)!=0: df = df.join(pd.DataFrame(data_detail).set_index('Filename'), on='Filename', how='inner' ).reset_index() if graph_kws['x'] is None: graph_kws['x'] = [None] if len(graph_kws['x'])==1 or graph_type=='scatter_matrix': drawer, graph_kws = drawer_px( graph_type, graph_kws, axis_ranges, log_axis ) try: fig = drawer(df, **graph_kws) except: fig = go.Figure() else: fig = go.Figure() return fig for arg in dropdowns: @app.callback( Output(f'graph-{arg}', 'options'), Input('table_info', 'columns'), Input('table_detail', 'columns'), prevent_initial_call=True ) def update_dropdown(col_info, col_detail): if col_info is None: col_info = [] if col_detail is None: col_detail = [] col = ['_'.join(c['name']) if c['name'][0]!='' else c['name'][1] for c in col_info ] col += [c['name'] for c in col_detail] return list(set(col)) for btn in list('xyz'): @app.callback( Output(f'{btn}_collapse', 'is_open'), Input(f'{btn}-button', 'n_clicks'), State(f'{btn}_collapse', 'is_open'), prevent_initial_call=True ) def open_collapse(clicks, is_open): return not is_open def parse_content(contents, filename): content_type, content = contents.split(',') decode = base64.b64decode(content) f = decode.decode('utf-8') try: data = COV19().load_string(f) info = data.info detail = data.data except: info = detail = None return info, detail def load_contents(contents, filenames): info = {} detail = {} for c, n in zip(contents, filenames): info[n], detail[n] = parse_content(c, n) info = pd.concat(info).unstack().rename_axis(['Filename'], axis=0) detail = pd.concat(detail).rename_axis( ['Filename', 'Date'], axis=0).reset_index() return info, detail @app.callback( Output('table_info', 'data'), Output('table_info', 'columns'), Output('store_detail', 'data'), inputs={'contents': Input('upload-csv', 'contents')}, state={ 'filenames': State('upload-csv', 'filename'), 'col_info': State('table_info', 'columns'), 'data_info': State('table_info', 'data'), 'data_detail': State('store_detail', 'data'), }, prevent_initial_call=True ) def update_csv( contents, filenames, col_info, data_info, data_detail): if data_info is None: df_info = pd.DataFrame() else: df_info = pd.DataFrame(data_info) col_info = pd.MultiIndex.from_tuples([c['name'] for c in col_info]) df_info = df_info.set_axis(col_info, axis=1).set_index( ('', 'Filename')).rename_axis('Filename', axis=0) if data_detail is None: df_detail = pd.DataFrame() else: df_detail = pd.read_json( data_detail, orient='records', convert_dates=['Date']) if contents is not None: info, detail = load_contents(contents, filenames) df_info = pd.concat([df_info, info]).drop_duplicates() df_detail = pd.concat([df_detail, detail]).reset_index( drop=True).drop_duplicates() col_flat = (['Filename'] + ['_'.join(c) for c in df_info.columns]) col_multi = [('', 'Filename')] + df_info.columns.to_list() df_info = df_info.reset_index().set_axis(col_flat, axis=1) columns=[ {'name': m, 'id': f, 'deletable': True} for f, m in zip(col_flat, col_multi) ] return df_info.to_dict('records'), columns, df_detail.to_json(orient='records') if __name__=='__main__': app.run_server(debug=True)
感想
便利だけど実際のcsvを扱うための変換が必要なのが面倒.今回は回避できたけど同じ出力先を持つコールバック関数は1つまでという制限も苦しい.